今回の記事では、「データベース初心者」や「サーバー構築初心者」向けの記事として、DBサーバーの構築時や運用時において、仮想環境の割り当てリソースの検討や、物理機器構成を検討する際に知っておいてほしいポイントを紹介していきます。
尚、当記事では特定のRDBMSに限定せずに、各RDBMS間で共通して実装されている機能や仕様をメインに紹介していますが、RDB製品によっては当記事で記載した機能が無かったり、仕様が異なっている場合もございます。
ご了承ください。
データベースとサーバーリソースの関係について
一言で「サーバー」と言っても、その用途や稼働するミドルウェアによって様々な種類があります。
そのサーバーのなかでも、「DBサーバー」は高いリソースが求められるサーバーになります。
まずは、一般的なRDBMS(OracleやSQL ServerなどのRDB製品)において、コンピューターリソースである「CPU」、「メモリー」、「ハードディスク」の役割を解説していきます。
物理機器の選定時や、仮想環境における割り当てリソースの検討時にはこのあたりを理解しておく必要があります。
DBサーバーにおける「CPU」の役割
DBサーバーにおいて、「CPU」は非常に重要な役割があり、その構成次第で、サーバーで稼働するデータベースのレスポンスを大きく左右します。
まずは、DBサーバーにおけるCPUの主な役割を箇条書きで紹介します。
- RDBMSの全般的な処理の実行
- SQL文の解析やコンパイルや実行
- データの抽出や更新処理の実行
- ロックやトランザクションの管理
- 自データベースに対するリクエストへの受付
- などなど…
このように、様々な処理をCPUで実行しており、CPUの性能が足りていない場合はそのすべての処理が遅くなります。
よって、DBサーバーに対して十分なCPUリソースを割り当てることは不可欠です。
DBサーバーの特徴としては、大量に発生するデータベースへのリクエストを次々と捌いていく必要があります。
そのため、高い並列処理能力が求めらます。
よって、多くのプロセスを同時に処理できるように、DBサーバーには多くのコア数を割り当てる必要があります。
また、データベースに対して要求されるリクエストは軽いものもあれば、テーブル内の大量のレコードを力づくで走査するような重いものもあり、CPU自体もクロック周波数が高く高性能なものが有利です。
ただし、RDBMSでは、後述する「メモリー」や「ハードディスク」もDBサーバーの性能を決める重要な要素になり、CPUリソースだけを潤沢に割り当てても効果は限定的です。
逆に言えば、適切にメモリーサイズを割り当てて、高速なディスクを使用することで、CPUの割り当てコア数を減らすことができます。
有償RDBMSの料金体系では、稼働させるサーバーのCPUコア数をもとにライセンス料が決まるものも多く、割り当てコア数を抑えることはランニングコストを抑えることにも繋がります。
他のリソースとのバランスが大切です。
DBサーバーにおける「メモリー」の役割
また詳しい解説は後述しますが、DBサーバーでは、「如何にデータのオンメモリーを維持するか」が重要になります。
その意味では、メモリーは非常に重要なリソース要素の一つです。
データベース内の各テーブルのデータの実体はハードディスク上の物理ファイルとして配置されます。
ただ、DBサーバーがSQLなどのリクエストを受け付けた都度、ハードディスク内の物理ファイルにアクセスして、全データから目的のデータを探しに行くのは効率的ではありません。
CPUやメモリーと比べると、ハードディスクの処理速度は圧倒的に遅いため、可能な限りハードディスクを参照する処理は減らす必要があります。
一般的なRDBMSでは、ハードディスクと比べるとデータの読み書きが高速な「メモリー」を活用して全体の高速化をはかる仕組みが多くあります。
RDBMSにおける「メモリー」の主だった役割は以下になります。
- 過去に読み込んだ(書き込んだ)レコードのデータ
- 過去に読み込んだインデックスデータ
- 過去に実行したSQLのコンパイル結果
- ストアドの変数などの領域
- 表のソートなどで使用する一時表領域
- などなど…
上記の各役割は大きく分けると、「RDBMS内のプロセス全体で共用するメモリー領域」と「各プロセスが個別で専有するメモリー領域」とで分かれますが、そのなかでもDBサーバーのレスポンスにおいて特に重要なのは、「キャッシュメモリー」とも呼ばれる、全プロセスが共有するメモリーです。
この「キャッシュメモリー」に割り当てるメモリーサイズを大きく割り当てれば割り当てるほど、低速なディスクへのアクセスは減り、高速なメモリー内でのデータアクセスが増加します。
よって、DBサーバーでは、ウェブサーバーやファイルサーバーといった他の用途のサーバーの倍から数倍のメモリーサイズを割り当てるのが一般的です。
DBサーバーにおける「ハードディスク」の役割
前述したとおり、RDBMSで管理する各データベース内のテーブル群のデータの実体は物理的なファイルであり、それはハードディスクに配置されます。
また、RDBMS内で一時的に利用される様々な処理は、各データベース内のテーブル群の物理ファイルと同様に、テンポラリーファイルとしてハードディスクに配置されます。
よって、いくら大容量のメモリーを割り当てて、可能な限りデータをオンメモリーで扱おうとしても、最終的にはハードディスクに配置された物理ファイルを参照することになります。
RDBMSでは、SELECTなどのSQLリクエストを受けてデータを読み込む先として、キャッシュメモリー内にデータがあればキャッシュから取得しますが、無ければハードディスクです。
また、UPDATEやINSERTなどの更新処理において、最終的な書き込み先はハードディスクです。
よって、DBサーバーにおけるハードディスクで重要なのは、データベースの物理ファイルを配置するディスクを最大限高速なもので選定することです。
RDBMSにおける「ハードディスク」の主だった役割は以下になります。
- RDBMSで管理するデータベースの物理ファイルの配置
- RDBMSの一時領域で使用する物理ファイルの配置
- RDBMSのトランザクションログなど各種ログの物理ファイル配置
- などなど…
前述したCPUやメモリーなどのリソースをいくら潤沢に割り当てても、データの物理的な読み込みや書き込み先であるハードディスクが低速であれば、やはり十分な性能は発揮できません。
DBサーバーのパフォーマンス関連の勘どころ
前項では、DBサーバーにおけるCPUやメモリー、ハードディスクといった主だったリソースとの関連性を簡単に解説しました。
当項では、新人データベース管理者向けに、DBサーバーの機器選定をしたり、パフォーマンス改善を進めようとする場合に知っておいてほしいポイントを紹介していきます。
ディスクは可能な限りSSDを選定しよう
前項でも紹介した通り、ディスクはDBサーバーのレスポンスにおいて非常に重要なリソースです。
よって必ず高速なディスクを採用してください。
尚、ディスクの速度の定義としては、ディスク自体の読み込み、書き込み速度と、そのディスクで使用されているインターフェイスの転送速度の組み合わせになります。
ディスク自体の読み書き速度(主に読み込み)は、後述する「RAID」を構成し、ディスクを数を増やすことである程度の向上は見込めます。
ただ、インターフェイスの転送速度は、その種類によって上限値が明確に決まっており、最終的にはそこがボトルネックになります。
よって当記事では、ディスクで使用するインターフェイスに重きをおいた速度に関する解説をして参ります。
まずは参考までに、サーバーで一般的に使用されるディスクの速度の違いを簡単に紹介しておきます。
| ディスク名 | 用途 | 速度 | 説明 |
|---|---|---|---|
| HDD(SATA) | PC向け | △ | 安価だが信頼性が低く低速。 サーバーでも使用できるがPC用途が一般的。 |
| HDD(SAS) | サーバ向け | 〇 | 高価な代わりに高い信頼性で比較的高速。 SASはSATAの倍の転送速度を有するインターフェイス。 |
| SSD(SATA) | PC向け | 〇 | 比較的高価で高速。 ただしインターフェイスのSATAがボトルネックで読み書き速度は頭打ちになる。 |
| SSD(SAS) | サーバー向け | ◎ | 高価で高速。 サーバー向けのSSDでは、信頼性の高いSAS接続が最も一般的。 |
| SSD(NVMe) | サーバ向け | ◎ | 非常に高価だが非常に高速。 インターフェイスはPCI Expressを使用しNVMeはSSD用に開発されたプロトコル。 トランザクションが発生する用途より読み込み速度に特化した用途で使われる。 |
上記のように、SSDと言っても、インターフェイスに「SATA」を使ったものと「SAS」、「PCIe(NVMe)」を使ったものがあり、SATAの場合、データ転送の最大理論値は「600MB/s」です。
「SAS」の転送速度の理論値はSATAの倍の「1.2GB/s」です。
さらに、PCIe(第4世代)にいたっては、理論値は「8GB/s」と圧倒的に高速です。
参考までに、ディスクの接続で使用される一般的なインターフェイスについても簡単に解説しておきます。
| IF種類 | 半二重/全二重 | 通信速度 |
|---|---|---|
| SATA | 半二重 | 600MB/s |
| SAS | 全二重 | 1.2GB/s |
| PCIe Gen4(NVMe) | 全二重 | 8GB/s |
半二重の場合、データは上りと下りで同時に通信ができません。
全二重であれば、上りと下りの通信を同時に流せます。
SATAインターフェイスを使用したSSDの場合、ディスク自体のデータ読み込み速度よりデータ転送速度のほうが遅いため、SSDの性能をフルで発揮させることはできません。
サーバー用のディスクでは、SATAやSAS、PCIe(NVMe)など、それぞれのインターフェイスでディスクを装着することができますが、DBサーバーのように、高い信頼性と処理速度が求められる場合は、可能な限りインターフェイスに「SATA」を使用したディスクを使用することは避けましょう。
【ポイント】ディスクの速さを計測してDB性能を予測する
ディスクの性能とは、データの読み込み速度や書き込み速度であり、それはフリーソフトなどを利用して簡単に計測が可能です。
DBサーバーをリプレイスする場合や別の環境に移行する場合、もし移行先のディスク速度を予め確認することができるなら、現在の環境とディスクの速度を比較して、現在の環境より遅くないディスクか否かを確認しておく必要があります。
もし新しい環境の方がディスクの速度が速いのであれば、DBサーバーを新しくしたらシステムが遅くなったとトラブルになる可能性は低いと言えます。
ディスクの読み込みと書き込み性能を試験する場合に有名なフリーソフトとしては「CrystalDiskMark」があります。
インストール不要で速度をチェックできるため、是非使用してみてください。

シーケンシャルなデータとは、ディスク内のデータの物理的な位置がまとまって並んでいる状態を指し、ランダムなデータとは、ディスク内のデータの位置がバラバラに配置された状態を指します。
従来のHDDでは、特にランダムに配置されたデータの読み書きが苦手であり、SSDはランダムなデータでも高速に読み書きが可能です。
技術者である以上、性能評価の際に、速い遅いといった分析を感覚でするのではなく、その速さや遅さを然るべき手法で計測し、具体的な数字で表現することは不可欠です。
ディスクはRAIDを構築して読み取り速度の向上をはかろう
ディスクの種類にSSDを選択することで処理が速くなると紹介しましたが、ディスクの速度には、ディスク本体自体の読み取りや書き込み速度以外にも、どのRAID構成を取るかによっても、速度は大きく変わってきます。
まず、一般的に「RAIDとは何か?」を簡単に解説します。
RAID(れいど)とは
「RAID」とは「Redundant Array of Independent Disk」の略称です。
複数のディスクを仮想的に集約し、一つの大きなデータ保存領域として扱えて、複数のディスクでデータを分散して読み書きする仕組みです。
一般的に、RAIDのメリットとしては以下の特徴があります。
- 複数のディスクを組み合わせて大容量のディスク領域が作れる。
- ディスク故障などの障害時にサーバーが停止しないように冗長化ができる。
- 分散したディスクを同時に読み取ることで読み取り速度の向上が狙える。
特に重要なのは、冗長化など耐障害性向上の観点と、読み取り速度の向上の観点です。
ディスクの故障でデータベースが止まってしまっては、そのデータベースを利用するあらゆるシステムが停止します。
また、データベースの処理が遅くなれば、そのデータベースを利用するあらゆる作業が遅れていきます。
RAIDにも幾つか種類があり、使用するディスクの数と、その組み合わせによって種類が変わります。
一部の種類では上記の特徴は当てはまらないのですが、大半のRAID構成では耐障害性と読み取り速度の向上が見込めます。
当項では、DBサーバーを構築するにあたって、最低限知っておく必要があるRAIDの種類も紹介しておきます。
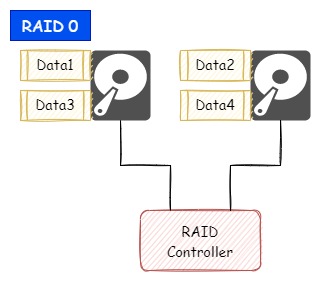
複数のディスクを一つの仮想的なディスクに統合して大容量ディスクを作る構成です。
例えば、100GBの容量があるディスクを3本使用してRAID 0構成を作ると、OSからは300GBの一つのディスクとして扱えます。
RAID 0は耐障害性が無いため、RAID 0を構成するディスクのうち、1本でも故障した場合は使用できなくなります。
また、ディスクの読み取り速度は、複数のディスクに分散されたデータを同時に読み取りにいけることから、RAID 0を構成するディスク本数が増えるほど読み取り速度の向上が見込めます。
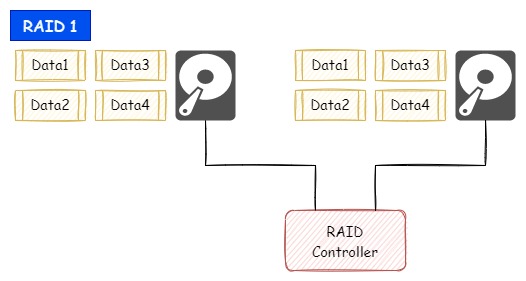
ディスク2本を使用して、その2本のディスクに同じデータを書き込みます。
そのため、ディスクが1本故障した場合は、残りの1本で継続して稼働できて、故障したディスクを正常な空のディスクに入れ替えれば、データが残っている残りの1本から空のディスクへデータ状態も復元します。
これを「リビルド」と呼びます。
最低限の冗長化構成をとる場合にはRAID 1を採用します。
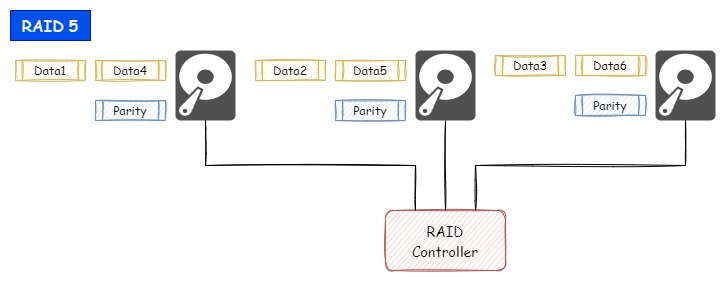
ディスク本数は最低でも3本が必要になります。
各ディスクに「パリティ」と呼ばれる誤り訂正符号ブロックを分散して格納することで、RAIDを構成するディスクのうち1本が故障しても継続して稼働できます。
パリティにはディスク1本分のデータ領域が必要になり、ディスク3本で構成するRAID 5の場合はデータ保存用として利用できるディスクサイズはディスク2本分になります。
前述したRAID 5と同様に、「パリティ」を分散して各ディスクに配置してどのディスクが故障しても影響がでないような仕組みになっています。
RAID 5ではディスクが1本故障しただけであれば稼働し続けることができますが、ディスクが同時に2本故障した場合は使用できなくなります。
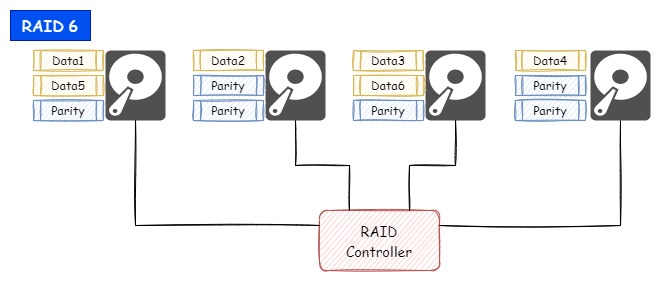
RAID 6ではディスクの同時故障が2本まで対応しており、同時に3本が故障した場合は対応できません。
尚、RAID 6の場合は、パリティ用のデータ領域としてディスク2本分が必要になり、RAID 6を構成する際の最低ディスク本数は4本からです。
また、RAID 5でも同様ですが、ディスク本数を増やすほど分散して配置されたデータを同時に読み込みすることができるようになるため、その分読み込み速度の向上も期待できます。
RAID 5と仕組みは似ていますが、RAID 5より耐障害性が向上する分、パリティへ割り当てるディスク本数が増えることで、使用できるデータサイズは小さくなります。
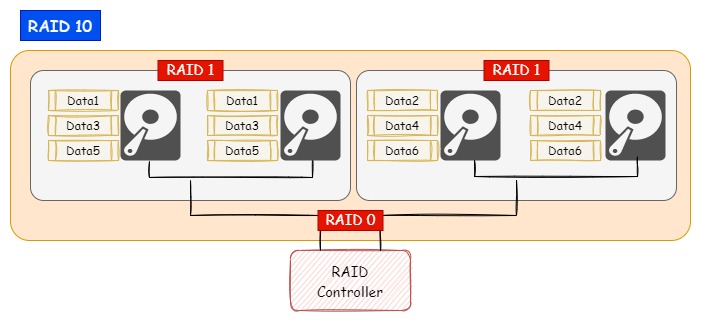
RAID 0(ストライピング)とRAID 1(ミラーリング)を組み合わせて構成するRAIDです。
RAID構成は2階層に分かれており、親の階層ではRAID 0として、配下の複数あるRAIDディスク(子階層)に分散して書き込みます。
子階層側のRAIIDディスクはRAID 1としてミラーリングして同じデータを二つのディスクに書き込みます。
このため、RAID 0で読み込み速度の向上を狙いつつ、RAID 1でデータの耐障害性も向上させます。
ディスクは必ず1本ごとにRAID 1でミラーリングが必要になるため、実際にデータを保存できるデータサイズはRAID 10を構成するディスク全体の半分になります。
メモリーサイズは可能な限り多く確保しよう
DBサーバーにおいて如何にデータをメモリーに載せた状態を維持できるかが重要だと前述しましたが、そのためには、そのDBサーバーに割り当てるメモリーのサイズは可能な限り大きくしておく必要があります。
サーバーを構成するパーツのなかでも、メモリーは比較的安価なパーツの一つです。
また、安価なわりに増設した場合の性能に対する向上度は大きく、コスパの良いパーツだとも言えます。
コア数とメモリーサイズが適切に割り当てされ、そのデータベースを利用するアプリケーションやデータベースのテーブル設計が無理のない合理的な状態であれば、CPU負荷が高い状態で推移することはなく、データのオンメモリー状態を維持しながら稼働させることが可能になります。
では、適切なメモリーサイズはどれぐらいかと言えば、そのサーバーで扱うデータサイズや負荷状況、データベースを参照するアプリケーションの作りや規模にもよっても変わってくるため、具体的に断言はできないのですが、個人的な目安としては以下のような構成でリソースを割り当てています。
| コア数 | メモリーサイズ |
|---|---|
| 4 | 8GB~16GB |
| 8 | 32GB~64GB |
| 12 | 64GB~128GB |
また、上記の値は、メモリーサイズに余裕を持たせて定義しており、上記目安値よりメモリーサイズが下回っても利用状況によっては十分正常に動作します。
なお、繰り返しになりますが、上記で提示した各値については、実際にはそのDBサーバーがどのOS上で稼働し、どのような用途で使用されるのかによって最適な値は変わります。
よって、大まかな参考程度に理解してください。
また、DBサーバー全体の使用可能メモリーサイズに対して、RDBMSに割り当てるメモリーサイズの「割合」で言えば、7割から8割ぐらいを割り当てるのが一般的だと思います。
よって、RDBMSに割り当てたいメモリーサイズを元に、DBサーバー自体に搭載するメモリーサイズを逆算するような感じになります。
データベースの物理ファイルの格納先ディスクを分離しよう
RDBMSでは、一つのインスタンス(RDBMS自体の実行環境)のなかに、用途ごとなどで分けてデータベース領域を複数作成することができます。
それらの各データベース領域は、物理的なファイルとして存在しています。
DBサーバーへの負荷がそれほど大きくない利用状況であれば、その複数作成したデータベース領域ごとの物理ファイルを一つのディスク領域に集約して格納してしまっても、性能的な観点で言えば問題はありません。
ただ、各データベースで扱うデータサイズが非常に大きかったり、そのデータベースにアクセスしてくるユーザーが多く、高負荷な利用状況の場合は、一つのディスク領域で複数のデータベースの物理ファイルを配置してしまうと問題が起こります。
一つのディスク領域で複数のデータベースの物理ファイルを配置したイメージ図が以下です。
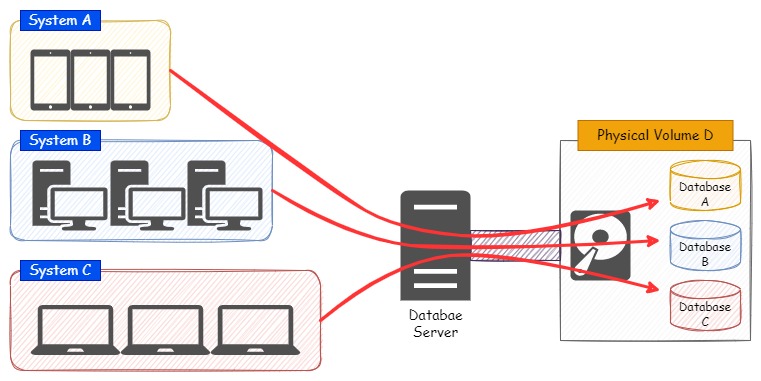
「System A」では「Database A」を使用し、「System B」は「Database B」を使用し、同様に「System C」は「Database C」を使用します。
各システムは複数のデータベースの物理ファイルが配置された単一のディスク領域にアクセスしています。
このディスク領域は、純粋な単一ディスクの場合でも、前述したRAIDを構成したディスクの場合でも考え方は同じです。
このような構成の場合、各システムがそれぞれ同じディスクにアクセスすることになり、ディスク自体の負荷やディスクを物理的に接続するSATAやSASといったインターフェイスへの負荷も集中することになります。
ディスクの処理(主にデータの読み込み)が間に合わないことで、CPUでは処理待ちのリクエストが滞留し、CPUの負荷の上昇に繋がり、サーバー全体の処理速度の低下といった状態まで連鎖的に悪化してしまいます。
そのため、可能な限り、以下のイメージ図のようにディスクを分けて、データベースの物理ファイルを配置してあげる必要があります。
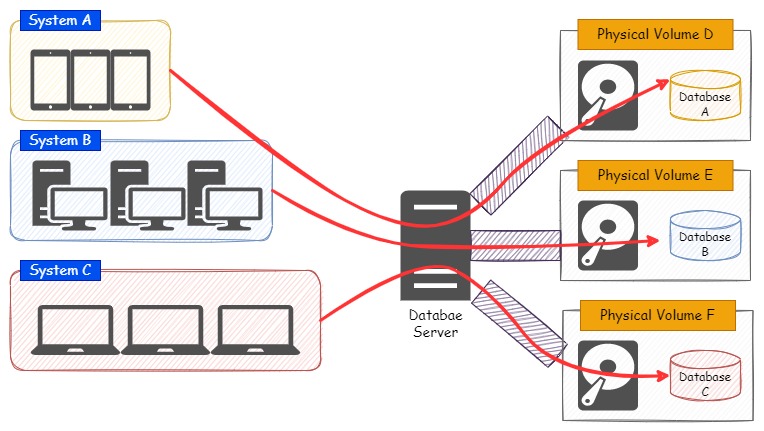
この構成にすることで、単一のディスク領域に負荷が集中することも無くなります。
尚、一つの物理的なディスクに対して論理的にパーティションを作り、そのパーティションごとにデータベースファイルを配置しても、物理的には一つのディスクに対して負荷が集中することに変わりはなく、ディスクI/Oの分散としては効果はありません。
ディスクI/Oの軽減といった性能改善の目的でディスク領域を分離する場合は、必ず物理的にディスクを増設して分ける必要があります。
データベースの内部仕様や性能指標の意味を理解しよう
データベースの性能改善に着目して突き詰めていくと、最終的にはRDBMS自体の内部仕様や各ハードウェアの性能指標の意味合いを適切に理解することが必要になってきます。
ここまでくると、「データベース初心者」は卒業と言えるでしょう。
データベースを知るうえで、理解しておいてほしいデータベースの内部仕様やハードウェアの性能指標の意味合いなどを簡単に紹介していきます。
データを読み込む際の最小単位
RDBMSごとで、データをディスクから読み込む際の最小単位を理解しておく必要があります。
この最小単位ですが、SQL Serverでは「ページ」、Oracleでは「ブロック」と呼びます。
共にデータの大きさは既定値では「8KB」です。
このデータの大きさはRDBMSのパラメーターで変更することができて、小さくすることで、データの利用効率が上がりますが、スループットは下がります。
大きくすると、スループットは上がりますが、データの使用効率は下がります。
SQL Serverの例でいえば、データベースを扱うデータの単位を、大きな順に以下のように並べることができます。
各データベース製品では、この「ページ」や「ブロック」を如何に効率よく読み込めるのかがとても重量です。
このページやブロック内には実際のレコードのデータやインデックスなどのデータを持っており、RDBMSは目的のデータを取得できるまでそのページやブロックを読み込みます。
また、メモリー内で保持する各データも、このページやブロック単位で扱われます。
また、RDBMSにとって欠かせない仕組みである「インデックス」では、インデックスで管理する情報のなかに、データの値と併せて、このページやブロックの物理的な場所に関する情報も保持している仕様の製品もあります。
その場合、インデックスを辿ることで、目的のデータが存在するブロックまでダイレクトに到達することができます。
このように、RDBMSの内部仕様のなかでも、ページやブロックといった要素は、データベースの仕組みを理解するうえで欠かせない仕様です。
参考として、SQL Serverの「ページ」に関して解説されている記事のリンクも紹介しておきます。
比較的読みやすい内容になっているので、参考にしてみてください。

IOPSとは1秒あたりのディスクのアクセス可能数
ディスクの性能指標では、「IOPS」があります。
これは「Input Output per Second」の略称であり、対象のディスクが1秒あたりにデータの読み書きを何回できる性能があるかを数値化しています。
当然これが大きければ大きいほど速いディスクだと言えます。
このデータの読み書きをする回数がわかっても、一回の読み込み時のデータサイズも定義されていないと、このIOPSの値が速いかどうかの正確な判断が付きません。
IOPSで性能を表す際に、その数値を算出した際に使用した一回あたりのデータサイズについても記載されており、4KB、8KB、16KB、などと定義されていたり、単位がKiBだったり都度異なります。
このIOPSを確認することで、このディスクでは、どれぐらいのデータ量を何秒で読み込み、書き込みできるかを計算で導き出すことができます。
ただし、実際にデータを読み書きする場合は、IOPSで計測したデータサイズの単位で実施されるわけではないのと、まとまったデータを読み書きした場合と、小さくバラバラに配置されたデータを読み書きする場合では、ディスク自体の読み込まれかたは異なるため、IOPSをもとに算出した時間の通りにはなりません。
参考程度の指標として理解しておいてください。
「スループット」は、1秒でどれぐらいの量のデータをディスクに読み書きできるかを計測します。
IOPSと似ていますが、IOPSは回数の指標であり、スループットはデータ量の指標です。
データベースサーバで発生するデータの読み書きは、小さい単位で細かく断続的に発生します。
よって、重要視すべきなのは、スループットよりIOPSです。
機器やリソース以外のパフォーマンス改善方法も知っておこう
今回の記事では、DBサーバーを対象に、物理機器や割り当てリソースに関連した解説をしてきましたが、データベースの性能改善手法は、ハードウェアを増強したり、割り当てリソースを追加するだけではありません。
それどころか、これらの対応は本来最終手段であり、その前に対応すべきなのは、アプリケーション側で実装している処理の効率化やSQLチューニング、RDBMSのパラメーターの見直しなどの、非ハードウェアに対する改善です。
よって、コア数を増やしたりディスク構成を変えるといったリソースを対象にした改善以外にはどのような対応方法があるかについても紹介しておきます。
SQLチューニングとインデックス付与
一般的なデータベースでは、データを取得したり更新する場合に「SQL」を実行します。
このSQLの書き方一つとっても、データベースに負荷を与える重い処理になったり、データベースへの負荷が抑えられた軽快な処理になったりします。
よって、対象のデータベース上で稼働するアプリケーションが遅かったり、特定の処理でサーバーの負荷が高くなるといった場合は、アプリケーション側で実装されているSQL生成処理を見直して改善を試みることは多々あります。
そのSQLを生成して実行している処理によっては、数秒のあいだに何千回、何万回と実行されているものもあり、このようなSQLを効率の良い処理に組み替えることで、劇的にレスポンスや負荷が改善されることも多いです。
こういったパフォーマンス改善の手法を「SQLチューニング」と呼びます。
また、「SQLチューニング」と併せて実施されるのが、不足しているインデックスの追加作業です。
一般的なRDBでは、テーブルに格納された特定のレコードを取得する場合、テーブル内の全レコードを上から順番に一行ずつ探すのではなく、「インデックス」を使用して、効率良く取得する仕組みが用意されています。
この「インデックス」については、当ブログの別の記事で解説しております。
良ければ以下のリンクもご参照ください。

RDBでは、この「インデックス」を有効に活用することで、大量にあるレコードから目的のデータを一瞬で取り出せる機能を実現しています。
このインデックスは非常に重要なデータでもあり、RDBMSでは優先的にメモリーに配置されていきます。
前述した「SQLチューニング」時に処理を解析した結果、特定の列にインデックスを設定してあげることでSQLの速度改善に繋がると判明すれば、その列にインデックスを新しく追加して、改善できたかを評価するといった作業を繰り返していきます。
処理のストアドプロシージャ化
一般的なRDBMSでは、標準的なSQLを独自に拡張して、JavaやCといったプログラミング言語のように条件分岐や繰り返しといった構文をSQLのなかに組み込んだ独自処理が作れます。
これを「ストアドプロシージャ(ストアド)」と呼びます。
このストアドプロシージャの特徴としては、RDBMSのメモリー上で展開、実行されることで、非常に高速に動作します。
この「ストアドプロシージャ」についても、当ブログの過去の記事で解説しております。
是非ご一読ください。
アプリケーション側で行っている処理をデータベース内のストアドプロシージャに移行することによって、対象の処理の高速化や負荷の大幅な軽減が見込めます。
インデックスの断片化の解消
RDBMSにおいて、「インデックス」は重要な仕組みだとお伝えしておりますが、このインデックスデータは徐々に劣化をし、それによりデータベースの性能は低下します。
インデックスの方式として一般的な「B-treeインデックス」を例にして解説します。
このB-treeインデックスの仕組み自体は、前述したSQLチューニングに関する文面内にインデックスについて紹介している当ブログの記事のリンクを貼り付けてあるため、そちらを参照していただければと思いますが、このインデックスの各ノードで保持しているデータは、本来論理的に整理されて、適切な順番で無駄無く並んで格納されています。
ただ、そのインデックスが設定された元のテーブルにレコードを挿入したり、レコードを削除するといった操作が繰り返されることで、そのノード内のデータの並びは崩れ、ノードは広く分離していきます。
その結果、インデックスが劣化する前の状態より多くのノードを参照しないと、目的のレコードを探し出せない状態になります。
これが「インデックスの断片化」です。
因みに、MicrosoftのSQL Serverに関するドキュメントでは、インデックスの断片化について、以下のように解説しています。
B ツリー (行ストア) インデックスの場合、インデックスのキー値に基づくインデックス内での論理的な順序と、インデックス ページでの物理的な順序が一致しないページがインデックスにあると、断片化が存在します。
挿入データベース エンジン、または削除操作が基になるデータに対して行われた場合は常に、インデックスが自動的に変更されます。
たとえば、テーブルに行が追加されると、行ストア インデックス内の既存のページが分割されて、新しい行を挿入するための場所が作成される場合があります。
時間が経つに従い、このような変更により、インデックス内の情報がデータベース内に散在 (断片化) するようになる可能性があります。
私が「ノード」と呼んでいるものが、Microsoftのドキュメントでは「ページ」と呼ばれています。
このように、インデックスは時間が経つにつれて「断片化」と呼ばれる性能劣化をしていくため、定期的にメンテナンスをしてあげる必要があります。
このメンテナンス方法としては、大きく二通り存在します。
断片化によってバラバラになったインデックスのデータを整理して並べ直します。
前述したMicrosoftの解説では以下のように表現しています。
行ストア インデックスの場合、データベース エンジン では、リーフ ノードの論理的な順序 (左から右) に合わせてリーフ レベルのページを物理的に並べ替え、テーブルおよびビュー上のクラスター化インデックスと非クラスター化インデックスのリーフ レベルのみを最適化します。
また、再構成によってインデックス ページが圧縮され、インデックスの FILL FACTOR と同じページ密度になります。
再構成の処理では、インデックス設定は残したまま、インデックスの内部的に管理しているデータを改めて並べ直して圧縮する処理であり、断片化が大きいほど時間も掛かります。
また、RDBMSの製品によっては、再構成の処理中はオフライン状態になり、対象のテーブルに対してアクセスできなくなるものもあります。
再構成処理中はサーバー自体の負荷も高まる可能性があります。
尚、再構成実施後も、断片化は完全には解消されずにある程度残ります。
インデックスデータを物理的に削除して、対象の列に対してインデックスを再度設定して作成し直します。
インデックスを消して作り直す処理です。
前述した「再構成」と比べると、こちらの方が大事のように感じますが、インデックスの物理的な削除や再作成の処理は、非常にレコード数の多いテーブルでも比較的短時間(超大規模なテーブルでないなら一瞬)で完了します。
また、再構築ではいったんインデックスを消して作り直すため、再構成のように、断片化が進んでいた場合ほど時間が掛かるといったこともありません。
新しくインデックスを作り直すことから、実施後も再構成のように断片化状態の残ることはありません。
上記の解説からもわかるように、一般的には再構成より再構築の方が合理的です。
最後に
今回の記事では、DBサーバーを構築したり運用する場合に知っておいてほしいコンピューターリソースの使われ方や、パフォーマンスに影響するハードウェアの仕組み、個人的に重要だと思うポイントを紹介しました。
これらの知識も机上の学習だけではなかなか身に付かず、本来は実務でトラブルに遭遇して苦労しながら学んでいくことになるのですが、出来ることなら事前に苦労やトラブルを避けて構築や運用に臨めるならそれが理想です。
今回の記事では、少しでもそういった場合の助けになればと思い、思いつくまま書いてみました。
誰かの参考になれば幸いです。
今回も長々と読んでいただきましてありがとうございました。
それでは皆さまごきげんよう!