今回の記事では、システム開発経験の無いシステム管理者向けに、最低限知っておいてほしい「データベースの基礎知識と機能」を紹介していきます。
尚、当記事は前編後編の二部制で作成しており、今回の記事は後編です。
【前編】について – DB知識の必要性・データベーとは・テーブル・インデックス・正規化・SQL –
前回の記事では、データベースを知っておいた方が良い理由を解説し、データベースの知識のなかでも、より基礎的な内容について紹介しています。
まだ前編を読んでいない場合は、よろしければ以下のリンクから先に読んでいただく方が理解が深まります。

データベースの基礎知識と機能
当記事では、前回の前編の内容よりも少しだけ専門的だったり高度な内容を紹介していきます。
それでも、あくまでデータベース初心者向けという前提で書いているため、なるべくわかりやすく解説するように努めます。
内部結合と外部結合
前回の記事では、データベースでは「テーブル」にデータを格納し、それらのテーブルは「正規化」をしながら合理的なレイアウトに分割されていくことを説明しました。
適切に「正規化」されたデータベース内のテーブルは、様々なデータが複数のテーブルに分割されて格納されており、そのバラバラに分解されたデータを必要によってくっつけて使用します。
その「正規化されたテーブルを用途によってくっつける」処理のことを「結合」と呼びます。
リレーショナルデータベースでは、この結合処理は必須の操作になるため、必ず大まかな概念や仕組みを理解しておきたい機能です。
尚、上記では「結合」とはテーブルを「くっつける」と表現しましたが、これは物理的にテーブルの定義を変更してテーブル同士をくっつけて一つの表にするのではなく、あくまでSQLの構文上で結合して一時的な一つの表にする処理です。
この結合には、大きく分けて以下の二種類が存在します。
外部結合(OUTER JOIN):一対多、多対一、多対多での結合
一対一や一対多などと言われても、その言葉だけで結合をイメージすることは難しいです。
その為、それぞれの結合の仕組みを簡単に紹介していきます。
内部結合(INNER JOIN)
二つのテーブル間の特定の列の値が同一のものだけを結合します。
以下のイメージ図では、社員マスタの「部署ID」列と、部署マスタの「部署ID」列を一対一で結合しています。
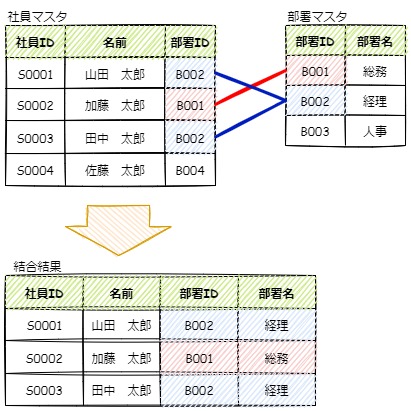
この結合では、お互いのテーブルの部署IDが完全に一致するレコードだけを取得することになります。
イメージ図下部の「結合結果」では、社員ID:S0004の佐藤さんのレコードは存在していません。
これは、社員ID:S0004の佐藤さんは部署IDに B0004 を持っているが、結合先の部署マスタ側には B0004 の部署IDの行が存在しないがためです。
このイメージ通りのSQLを書くと以下の様なSELECT文になります。
--社員マスタと部署マスタを内部結合します。 SELECT 社員マスタ.社員ID ,社員マスタ.名前 ,社員マスタ.部署ID ,部署マスタ.部署名 FROM 社員マスタ INNER JOIN 部署マスタ ON 社員マスタ.部署ID = 部署マスタ.部署ID;
左外部結合(LEFT OUTER JOIN)
左側の表すべてのレコードと、結合対象の列の値が一致するレコードを右側の表から結合します。
以下のイメージ図では、社員マスタの「部署ID」列と、部署マスタの「部署ID」列を一対多で結合しています。
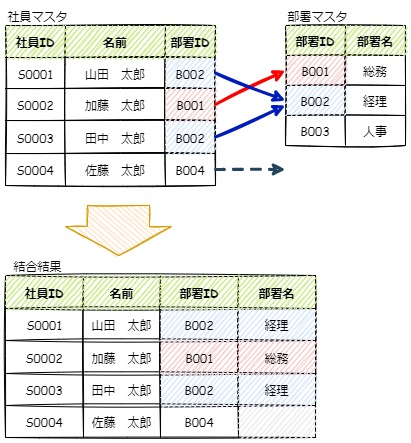
この結合では、左側のテーブルを全て取得し、右側のテーブルには左側と同一の値を持ち結合可能な列は結合し、右側のテーブルに結合対象のレコードが存在しなければNullとして扱います。
イメージ図下部の「結合結果」では、左側のテーブルの社員マスタは全行取得しており、右側の部署マスタと結合できた場合は部署名も取れていますが、社員ID:S0004の佐藤さんのレコードでは、部署IDが部署マスタ側に存在しないため、部署名は空白になっています。
このイメージ通りのSQLを書くと以下の様なSELECT文になります。
--社員マスタと部署マスタを左外部結合します。 SELECT 社員マスタ.社員ID ,社員マスタ.名前 ,社員マスタ.部署ID ,部署マスタ.部署名 FROM 社員マスタ LEFT OUTER JOIN 部署マスタ ON 社員マスタ.部署ID = 部署マスタ.部署ID;
右外部結合(RIGHT OUTER JOIN)
右側の表のすべてのレコードと、結合対象の列の値が一致するレコードを左側の表から結合します。
以下のイメージ図では、社員マスタの「部署ID」列と、部署マスタの「部署ID」列を多対一で結合しています。
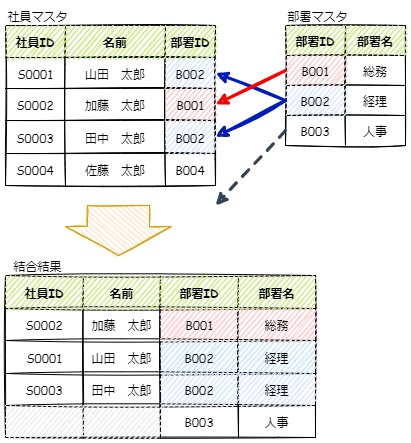
この結合では、右側のテーブルを全て取得し、左側のテーブルには右側と同一の値を持ち結合可能な列は結合し、左側のテーブルに結合対象のレコードが存在しなければNullとして扱います。
イメージ図下部の「結合結果」では、右側のテーブルの部署マスタは全行取得しており、左側の社員マスタと結合できた場合は社員IDや名前も取れていますが、部署マスタの部署ID:B0003で結合できる社員マスタのレコードは存在しないため、部署ID:B0003のレコードの社員IDと名前は空白になっています。
このイメージ通りのSQLを書くと以下の様なSELECT文になります。
--社員マスタと部署マスタを右外部結合します。 SELECT 社員マスタ.社員ID ,社員マスタ.名前 ,部署マスタ.部署ID ,部署マスタ.部署名 FROM 社員マスタ RIGHT OUTER JOIN 部署マスタ ON 社員マスタ.部署ID = 部署マスタ.部署ID;
他にも、多対多での結合も有りますが、少し特殊なので当記事では割愛します。
これらの内部結合や外部結合については、リレーショナルデータベースを扱ううえでは必須の知識です。
リレーショナルデータベースでは、前編に紹介した正規化の考え方でテーブルが分割されていることで、欠損の無いデータを扱うためには、必ず結合をして複数のテーブルを一つの表にまとめる必要があります。
後、前述したLEFT OUTER JOIN 及び RIGHT OUTER JOIN についてはどちらをベースのテーブルとして結合するかの違いであり、実務上はわざわざ使い分けることはせず、逆に結合する向きが都度違っているとSQLの解読が面倒でもあるため、外部結合が必要な場合は処理がイメージしやすいLEFT OUTER JOINで統一したほうが無難です。
リレーショナルデータベースにおいて「結合」はとても重要です。
結合をすることで初めて各テーブルは一つの完全なデータになります。
SQLを書けなくてもよいですが、内部結合と外部結合の考え方は知っておいてほしいところ。
ビュー
当項では、データベースにおける機能的な機能の「ビュー(VIEW)」を紹介していきます。
当記事の前編では、「SQL」について紹介しました。
そのなかで、SELECT文でレコードを取得することができると説明していますが、ビューは、そのSELECT文を予めデータベース内に登録しておき、必要な時に呼び出せるといった機能です。
作成したビューはテーブルと同じように扱えるため、例えばSELECT文のFROM句でビュー名を指定して検索することができます。
その代わり、基本的にはビューを指定してデータの更新や削除はできません。
あくまでレコードの参照(SELECT)をする用途でのみ使用します。
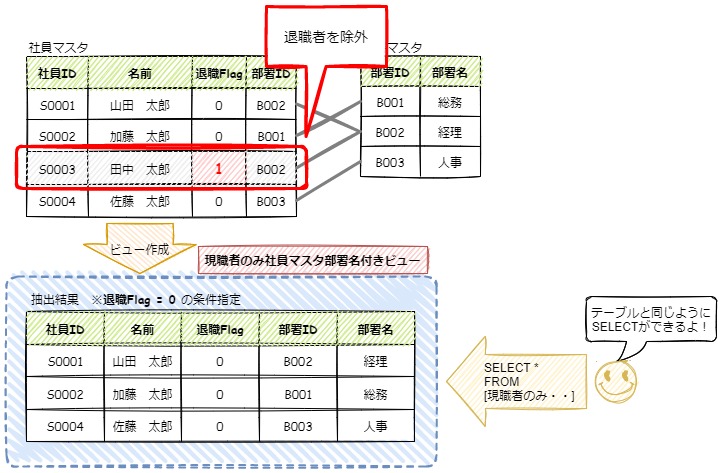
一般的にはビューを作成することで以下の様なメリットやデメリットが存在します。
- 頻繁に利用するSQLや複雑なSQLをビュー化しておくことでSQLの作成を省略することが可能。
- 別のテーブルと結合することができて、サブクエリのように利用できる。
- 顧客マスタから個人情報だけを省いてビュー化するなど、扱いやすい仮想テーブルとしても使用可能。
- セキュリティの観点から実テーブルを参照させることなくデータへのアクセス手段を提供できる。
上記のイメージ図にもあるように、社員マスタを参照する際には、常に退職Flagが0のレコードだけを参照しているなら、社員マスタを直接参照するのではなく、退職Flagが0を条件にして作成したビューを参照した方が合理的です。
また、仮想的なテーブルとしても利用できるため、別のテーブルとビューを結合して一つの表も作れます。
データベースではデータベースにアクセスできるユーザーを管理することができて、権限の低いユーザーからアクセスされた場合は、実テーブルは参照できないようにしてビューだけを参照させるといった制御も可能です。
- 複数のビューをサブクエリ的に入れ子した複雑なSQLを作成した場合に処理を把握するのが困難になる。
- ビューで参照しているテーブルの定義が変更(列の削除など)になった場合にビューがエラーになり影響範囲の把握も困難。
ビューはテーブルのように扱えることで、複数のビューを組み合わせたSQLが作れます。
個々のビューの中身は、それぞれが何らかのSQLで集計された表だったり、複数のテーブルで結合された表だったりします。
それらが組み合わされたSQLでは処理が非常に複雑になり、個々のビューの処理を紐解くには個々のビューのCREATE文を確認する必要があり、それらの解析は非常に困難になります。
解析が困難なほど複雑なSQLが内部的に実行されることで、前編でも紹介した「インデックス」を効果的に効かせるSQLを作成することも困難になり、処理が遅く負荷が高いSQLが出来あがる可能性も高くなります。
また、ビューは参照先のテーブルに依存しており、実テーブルのテーブル定義が変更になった場合はそれに併せてビュー側も修正しないといけません。
ただ、参照先のテーブルはどのビューが自身を参照しているのかを把握する術が無い為、大量にビューを作成して使用している環境の場合は、テーブルの定義変更により影響をうけるビューの把握も非常に困難になる場合があります。
これらの理由により、ビューは非常に便利な機能であると同時に、データベースの管理やシステムのレスポンスにおいてデメリットもあります。
よって、無暗に必要性の低いビューを量産し、そのビューを使ってシステムを稼働させていたりすると、後から意図しない不具合やトラブルに見舞われる可能性もあるため、計画的な利用をおススメします。
ビューはメリット、デメリットがある機能であり、ビューを作成する場合は慎重に必要性を検討してから実施しよう!
また、ビューを作成したら、後々のテーブル定義の変更に備えて、適切に管理していきましょう!
ストアドプロシージャ
当項では、データベースにおいて非常に重要な機能のひとつ「ストアドプロシージャ」を紹介していきます。
「ストアドプロシージャ(通称:ストアド)」をうまく活用することで、貴方の会社で動いている業務システムは劇的に速くなるかもしれません。
ぜひ詳しい機能を覚えていってください。
「ストアド」ってなにさ?
まずはWikipediaの記事を抜粋しておきましょう。
ストアドプロシージャ (stored procedure) は、データベースに対する一連の処理をまとめた手続きにして、関係データベース管理システム (RDBMS) に保存(永続化)したもの。 永続格納モジュール (Persistent Storage Module) とも呼ばれる。ストアドプロシージャの格納先はRDBMSの実装により異なり、RDBMSのデータ辞書や専用の格納スペースが用いられている。
「ストアドプロシージャ」とは、条件分岐や繰り返し処理が必要な複雑な更新処理などをRDBMSで用意された構文を用いてプログラムとして作成、実行できる機能です。
ストアドプロシージャでは、例えばSELECT文を実行し、その実行結果をカーソル(ADOで言えばレコードセットと様なもの)に格納し、その行数分ループさせてレコードの値を元に条件分岐して別のテーブルのデータを更新するといった複雑な処理が行えます。
業務システムなどでは、そのシステムの設計方針によっては一切ストアドを使用せずに構築している場合もあり、業務システムにおいて必ず使われているものははありません。
前編に紹介した「SQL」をクライアント側からデータベースに対して実行し、都度必要なデータを取得したり、特定のデータを更新するといったやり取りを繰り返す実装で問題がない場合も多く、そのような実装方式でアプリケーションを開発したほうがデータ管理場所とアプリケーション実行場所が明確に分離できて作りやすかったり管理しやすかったりします。
ただ、前述した通り、ストアドを上手く活用することで、システムのレスポンスを劇的に向上させることができます。
そのため、具体的にどのようなケースでストアドを活用すべきかを次項で紹介していきます。
尚、次項では、業務で使われるシステムのなかでも「デスクトップアプリケーション」とか、「クライアント・サーバー型システム」などとも呼ばれる、各個人のパソコンにインストールして使うようなアプリケーションを例に説明していきます。
クライアントとサーバー間でのやり取りが多いと遅い
クライアント・サーバー型システムでよくある実装方式として、クライアント側のアプリケーション側で処理ごとに都度SELECT文やUPDATE文などのSQLを生成し、データベースサーバーに対してSQLを投げて、その結果を直接クライアント側で受け取るといったやり取りを繰り返す実装です。
単純な処理であればクライアントとDBサーバー間の通信も一瞬で済みますが、当然一瞬では済まない処理も実装せざるを得ない場合も多々あります。
例えば、よくある処理としては、データベースから特定の条件に合うレコードをSELECT文で大量に取得して、その取得してきたレコードの行数分のループ処理のなかで、別のテーブルに対して更にSELECTして更新条件に合う場合は対象のテーブルの行に対して更新をするといったものがあります。
そういったケースでは、アプリケーション側の一つの処理のなかで、以下のイメージ図のようなやり取りをクライアントとDBサーバー間で繰り返します。
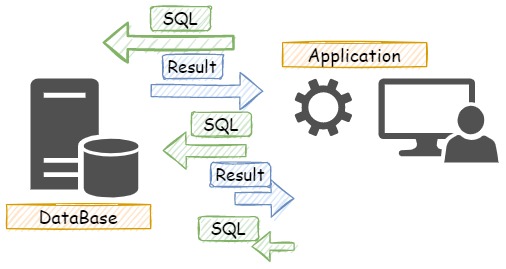
このクライアントとサーバー間の通信が、例えば数回程度であれば、高負荷なSQLを実行しない限りは一瞬で済む場合も多いですが、この繰り返し処理が100回必要だったり、1000回だったり、それ以上だったりすると処理のレスポンスは目に見えて遅くなります。
処理を遅くさせる要因を以下で解説します。
クライアント・サーバー方式のシステムにおいて、クライアントとサーバーは必ずネットワークを介して通信します。
本来ネットワークの通信速度は非常に速く、クライアントとサーバー間の通信でも人間の感覚では一瞬でデータのやり取りができているように感じます。
ただ、実際には、ネットワーク構成やネットワーク上の通信経路、クライアントとサーバー間の物理的な距離などによって、その「一瞬」の時間にも大きな開きがでます。
例えばクライアントとサーバー間でPingを実行して応答時間を測定した場合に、その時間が1ミリ秒と10ミリ秒では、人間の感覚では大きな違いを感じることは難しいですが、この通信が100回発生すれば、その時間の差は約1秒程度まで広がります。
1秒の違いであれば、人間の感覚でも僅かに遅延を感じることができます。
また、ネットワーク構成によっては、DBサーバーはデータセンターで稼働しており、VPNを介して各拠点のクライアントと通信しているといったケースの場合は物理的な通信経路も長くなり、VPNにおいて大きな通信帯域を確保するのが難しい場合も多く一気に通信速度が低下します。
その様な場合は、Pingの応答時間は前述した10ミリ秒ではなく、更に100ミリ秒台まで低下するといったことも多く、仮に100ミリ秒台であれば100回通信を繰り返した場合の時間の差は10秒まで広がります。
処理によっては致命的な遅延になります。
一般的に、データベースはクライアントからSQLを受け取った際に、以下の様な過程を経てSQLを実行します。
- 構文の解析
- コンパイルの実行
- SQLの実行
初めに渡されてきたSQLの構文解析を行い、構文に誤りがあるかをチェックします。
その後、渡されてきたSQL文をデータベース側で実行可能な状態に「コンパイル」します。
このコンパイルが完了した後にようやくSQLが実行されて、処理対象のテーブルへの参照や更新が実行されます。
ただ、このコンパイル処理はデータベースにとっては非常に重い処理です。
このコンパイルも個々の処理は一瞬ですが、この処理も繰り返し処理のなかで何度も頻繁に実行されることで、一連の処理の遅延の原因となります。
ストアドに置き換えることで処理速度が大きく改善
ストアドプロシージャでは、前述した処理の遅延の要因を解消してくれます。
故に、運用しているシステムで処理遅延などの性能問題が発生した場合に実施すべきいくつかの対策のなかでも、非常に効果が見込める対策の一つです。
クライアント側のアプリケーションからSQLを生成してデータベースに投げる処理から、データベース側でストアドを作成し、クライアント側アプリケーションからそのストアドを実行させる処理に変更した場合に、クライアント側アプリケーションの処理で大きく変わる部分としては、何度も都度SQLを生成してデータベースに投げていた処理が、データベース内のストアドを一度だけ呼び出して、その処理結果を受け取る処理に変わったところです。
処理をストアド化した場合のイメージ図は以下です。
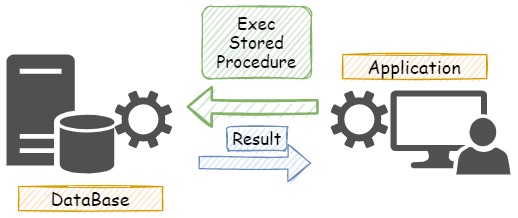
上記の図を見る限り、クライアントとサーバー間のやり取りが激減しているのがわかるかと思います。
ここが非常に大きなポイントです。
このようにストアド化することで、クライアントとサーバー間のやり取りを大きく減らすことができますが、それがどのような処理速度の高速化に繋がるのかについて、以下で簡単に解説していきます。
前項では、ネットワークを何度も介しながらクライアントとサーバーが通信をすることが処理の遅延に繋がると説明しましたが、ストアド処理に置き換えた場合は、クライアント側アプリケーションの処理としては、データベース側で作られたストアドを呼び出して、実行結果を受け取るだけです。
ストアドの内部処理でどれだけ大量にループしながらSQLを発行しようが、それらの処理はネットワークを介さずにDBサーバーのなかだけで処理が完結し、呼び出し時の通信と、ストアド実行完了時の実行結果を返す通信の2回しか発生しません。
それにより、例えば前項で解説した例では、VPNを介すことで応答速度が100ミリ秒台だった場合に、それをストアド化することでその通信時のボトルネックを0にします。
当然処理は短時間で完了するようになり、変更前の処理がループ処理などで大量のSQLを何度も繰り返し実行するような処理の場合は劇的に処理速度の改善が見込めます。
前項では、クライアント側アプリケーションがSQLを生成してデータベースに投げるたびに、データベース側ではそのSQLの構文を解析してコンパイルを実行すると説明しましたが、ストアドプロシージャの場合は、ストアドを作成してデータベースに登録する際に構文解析及びコンパイルも併せて実施され、登録済みのストアドをアプリケーションが呼び出す際には、構文解析処理やコンパイル処理は走りません。
よって、呼び出しの都度コンパイルを実行してサーバーのCPUリソースを消費することもなく、効率良く処理を実行できるようになります。
これらのように、ストアドプロシージャを効果的に利用することで、システムのレスポンスは劇的に改善する可能性があります。
ネットワークを介さずに、コンパイルも発生しないことで、ストアドは実質ほぼオンメモリーで実行されるようなものであり、非常に高速です。
良いことづくめの「ストアドプロシージャ」ですが、デメリットもあります。
念のため、そのデメリットも簡単に紹介しておきます。
ストアドのデメリットはプログラム管理の煩雑化
もしストアドを利用せず、クライアントアプリケーションのみがプログラムを実行し、データベースサーバーはデータベースを提供するだけであれば、システム開発者はクライアントアプリケーション側のプログラムだけを厳密に管理することになりますが、そこにストアドが加わる場合は、データベース側に登録したストアドの処理もクライアントアプリケーションのプログラムと並行して管理する必要が出てきます。
アプリケーションのプログラムを管理と一言で言っても、その中身は、バージョン管理、変更箇所の差分管理、テスト環境版や本番環境版、イレギュラーな機能改修版などの複数の枝葉に分かれたバージョンの管理、複数人での開発時のプログラムマージ管理などの、プログラムに纏わる様々な項目を管理する必要があり、大規模なシステムの場合は整合性を維持して管理することは、豊富な経験と相応の労力が必要です。
この管理が適切にできていないと、デグレード(過去の不具合が再発したり改修を機に品質が悪くなること)が発生したり、実装した機能が抜け落ちたりするなど、アプリケーションにとって致命的な問題を引き起こします。
そういったプログラムの管理対象として、クライアントアプリケーションとは実行環境が全く異なるストアドプロシージャが追加されることで、プログラムは一元的な配置では無くなり、より管理は複雑になります。
管理が複雑になることで、意図しない不具合を発生させる可能性が高まります。
プログラムの管理はあくまでシステム開発会社などの開発者側の話になり、そのシステムを使うユーザー側がそれを意識する必要は本来無いのですが、システム開発における開発者側の事情についても知っておくに越したことはないので、覚えておいてください。
ストアドプロシージャはお使いのシステムの性能問題で困ったときには是非試してみてほしい機能です。
DBサーバーをDCに移設したらシステムが遅くなったとか、DBサーバーの負荷が高くて困っているといったときなど、ストアドがその問題を解消してくれるかも知れませんよ!
データベース・トリガー
当項では、知らなくてもデータベースは使えるが、使い方を知っているとより便利にデータベースを利用できる「トリガー」について紹介していいきます。
まずはWikipediaの記事を簡単に引用します。
データベーストリガは、表に対するイベントに反応して自動的に実行される操作を意味する。
トリガはデータ操作言語によるデータ状態の管理を自動化するために用いられる。
トリガを利用することで、データ操作の限定、操作の記録、変更操作の監査などを行うことができる。
とのことです。
トリガーをテーブルに対して設定することで、特定の条件に合うイベントが発生すると、自動的に任意の処理が実行できる機能です。
これだけの説明では、なかなかその便利さが伝わらないかと思うので、もう少し具体的にトリガーの機能内容を紹介していきます。
トリガーの主な種類
トリガーはデータベース内の特定のイベント発生に起因して任意の処理を自動実行するための機能です。
まずは、そのイベント内容によって大きく三つの種類に分かれます。
- ログイン・ログアウトトリガー
- DDLトリガー
- DMLトリガー
このタイプのトリガーはRDBMSによっては対応していないものもあります。
ユーザーがログオンした際にログテーブルにINSERTするといった監査目的での利用が想定されます。
個人的には使用したことはありません。
データベースのスキーマ関連の変更を検出したり履歴に残すといった目的で使用されます。
こちらも個人的には使用したことはありません。
システム開発者が通常使用するのはこの「DMLトリガー」になり、「トリガー」と呼んでいる場合はこの「DMLトリガー」のことを指しています。
当記事でもDMLトリガーとは呼ばずに「トリガー」と呼称して解説をしていきます。
トリガーの主な機能
当項では、トリガーの主な機能や使い方を簡単に紹介していきます。
トリガーとはテーブルに対してDMLが発生した際に、別の処理を自動実行させることができる機能です。
この「DML」ですが、具体的には以下です。
- INSERT
- UPDATE
- DELETE
トリガーを作成する際には、SQLの「CREATE TRIGGER」ステートメントを実行し、その構文のなかで、上記のどのDML実行時に動作させるのかも指定します。
例えば対象のテーブルのレコードに対して、UPDATEが実行された場合に動作させるとか、対象のテーブルにINSERTが発生したら動作させるといった指定方法になります。
また、トリガーの処理は、前項で紹介したストアドプロシージャのように変数や条件分岐などの制御構文が使用できます。
それにより、複雑な処理をトリガー内で実装させることが可能です。
後、トリガー内の処理では、変更前と変更後のレコードを同時に参照することができます。
例えば、UPDATEトリガー内の処理で、更新前のレコードと更新後のレコードをINNER JOINで結合したSELECT文を実行し、両レコードの特定の列の値を比較し、IFなどの条件分岐をしたうえで別のテーブルを更新するなどの処理をすることができます。
また、この変更前と変更後のレコードを比較して、条件に適合しない場合は何もしないというトリガー処理も作れます。
トリガーの便利な部分の一つとしては、上記のように変更前と変更後のレコードを同時に参照できるところにあります。
トリガーの活用例
これまで紹介してきたデータベーストリガーですが、具体的にどのように活用すべきかわかり辛いかもしれません。
そのため、実際の活用例を紹介していきます。
マスタ系テーブルではなく、データテーブル系のカラムで使用されることの多いのが、そのレコードを作成した日時や更新した日時を格納するカラムです。
このようなカラムはレコードをINSERTする処理や、UPDATEする処理で実行するSQLのなかで現在に日時を値としてセットすることも多いのですが、そのテーブルのINSERTトリガーやUPDATEトリガーに作成日時や更新日時の値を更新するトリガーを設定しておく活用方法があります。
そのトリガーを設定しておくことで、データの作成処理や更新処理では必ず作成日時や更新日時がセットされ、何らかの業務システムを介した処理以外にも、データベース接続ソフトを介してテーブルを直接開いて更新するような場合でもトリガーが動いて自動的に更新されます。
トリガーに設定しておくことで、更新日時などの更新処理漏れを気にすることは無くなります。
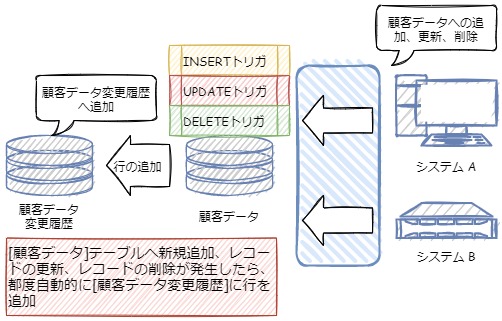
例えば顧客データなどの重要なテーブルに対しての変更は履歴データとして変更履歴用のテーブルで管理させたい場合に、業務システムで顧客データへの更新処理と併せて履歴データを作成する処理を実装させるやり方もありますが、例えば別のシステムなどでも同様に顧客データを更新する処理があるなら、履歴作成処理を同じように実装する必要があり面倒です。
そんな時は、顧客データ側でINSERTやUPDATE、DELETEの処理ごとにトリガーを実行し、そのトリガー内で変更履歴用のテーブルにレコードを作成する処理を入れることで、業務システム側では変更履歴データの作成処理まで実装する必要が無くなり無駄がありません。
同一のデータベースを異なるシステムが利用することも多いです。
その異なるシステムでは開発会社も異なっている場合もあります。
テーブルのレコードを作成したり更新する処理では、テーブルAを更新した場合に、必ずテーブルBも更新しないと不整合が発生するといったデータ更新時の決まりがあった場合に、それを異なるシステム開発会社間で同じように実装してもらうのは結構面倒です。
また、片方のシステム開発会社では、テーブルBを更新してからテーブルAを更新するといった感じで順番が入れ替わってしまうかも知れません。
その場合は、お互いの更新処理が同時に発生することでロックし合って処理が終わらないという「デッドロック」という状態になる恐れもあります。
そのような場合は、テーブルAの更新トリガーにテーブルBの更新処理を組み込んでおくことで、同じデータベースを共有するシステム開発会社はテーブルBの整合性を考慮する必要は無くなります。
上記の活用例のうち、顧客マスタの変更履歴自動作成、及び異なるシステム間での更新処理の共通化についてのイメージ図を以下で用意してみました。
トリガーのデメリットやリスク
非常に便利なトリガーですが、使い方を誤ると非常に危険です。
当項ではトリガーのデメリット、リスクも紹介していきます。
トリガーはテーブルの更新元が何であろうが自動的に実行されます。
その為、テーブルにトリガーが設定されていることを知らずにテーブルに対して更新を掛けようとした場合は、作業者が想定していない更新処理が走ることになります。
トリガーが一部の技術者から怖がられる要因がこれです。
「勝手に更新処理が動く」のはやはり意図しないトラブルを招きかねないので、トリガーはしっかり管理して運用することが大切です。
トリガーではレコードの作成や更新の度に自動的に実行されます。
RDBMSによってこの辺りの仕様は異なりますが、製品によっては、内部的には更新前の行もトリガー内で参照できるように、メモリー内に一時的に移送するといった処理が動くものもあります。
その処理単体では一瞬の処理ですが、大量に更新を掛ける場合に一件ずつこの処理が走れば当然処理は遅くなります。
また、トリガー内で更新を複数のテーブルに対して掛ける場合に、それらのテーブルに対する更新処理は前述したトランザクション内で処理されます。
テーブルA単体を更新する分には一瞬だったのが、テーブルBやテーブルCも併せて更新を掛けるとなると、やはり時間が掛かるようになります。
他のプロセスからのロック待ちも増える可能性もあります。
これらも注意が必要です。
データベース・トリガーは初心者向きではなく比較的上級者向きの機能です。
ただ、上手く活用することで、データベース内の様々な処理を共通化することができて大変便利なので、チャンスがあれば使ってみましょう!
トランザクション管理とロック
当項では、データベースにおいて重要な「トランザクション」と併せて「ロック」について紹介していきます。
尚、トランザクションやロックについてしっかりと理解してもらおうとした場合は、ブログの1記事の投稿程度のボリュームで書き切れるものでもないため、大まかな仕組みや概念が理解できる程度の解説を目指します。
まずは、Wikipediaの記事を引用しましょう。
トランザクション処理(トランザクションしょり、英: transaction processing)とは、トランザクションと呼ばれる不可分な操作から構成される情報処理の形態。
トランザクションは、データベースをある一貫した状態から別の一貫した状態へ変更するアクションを1つに束ねたものである。トランザクション処理は、既知の一貫した状態のデータベースを維持するよう設計されており、相互依存のある複数の操作が全て完了するか、全てキャンセルされることを保証する。
データベースでは、データの整合性を維持し適切に更新できるようにする仕組みがあり、そのなかの一つが「トランザクション」であり、そのトランザクションでは「ロック」機能を利用します。
過去にトランザクション管理やロックについて簡単な記事を当ブログで公開しております。
良かったらこちらもご参照ください。
この記事でもあるように、「ロック」とは、レコードの更新時に他のプロセスから同時に更新されてデータの不整合が発生しないように、レコードの更新中は自分以外のプロセスからの更新処理を待たせる仕組みを指します。
上記の記事では、RDBMSのSQL Serverを前提に書いておりますが、SQL Serverにおける既定のロックの仕様では、ロックされている行に対するSELECTでの参照も許されません。※参照させることも可能
ただ、この辺りのロック時の仕様は、RDBMSによって異なり、Oracleにおける既定のロックの仕様の場合は、ロックされている行でもSELECTはできます。※参照を許さないようにすることも可能
リレーショナルデータベースでは、データの整合性を担保する仕組みとして「ロック」が非常に重要です。
また、「トランザクション」とは、データの更新処理において一塊として扱う必要があり、これ以上の分割ができない一連の処理を指します。
トランザクション管理の紹介
前述したトランザクションですが、具体的な例をイメージ図を元に説明していきます。
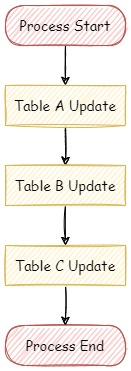
まず、以下のように「Table A」「Table B」「Table C」を順番に更新する処理を仮定します。
それぞれのテーブルはリレーションの関係にあり、この三つのテーブル全てに更新を掛けないとデータの不整合が発生する想定です。
この一連の更新処理で、例えば以下のイメージのように、Table AとTable Bへの更新処理は成功したが、Table Cへの更新処理でエラーが出て失敗した場合はどうなるでしょうか。
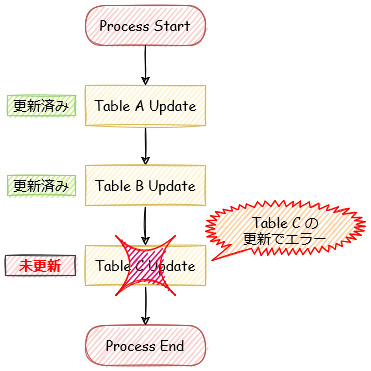
この三つのテーブルはリレーション関係にあり、Table Cの更新が掛からなかった場合はデータの不整合が発生してしまいます。
これでは信頼性の高いシステムは作れません。
この問題を解決するには、一連の更新処理のうち、全て成功したか、どれかで失敗したかを検出する必要があります。
また、すべての更新処理が成功するまでは実データへの更新は保留しておき、すべての更新処理が成功したら実データへの反映を実施し、もしどれかの更新処理に失敗したら、そこまで更新したデータはなかったことにして元に戻す必要があります。
このように、データの更新を保留にして後からまとめて実データに反映させることを「コミット」、エラーなどをきっかけに保留にしていた更新処理をなかったことにすることを「ロールバック」と呼びます。
ロールバック:保留にしていたデータ更新処理を取り消してなかったことにする
まずは、一連の更新処理でエラーが発生せずに、正常にコミットまでできた場合のトランザクション処理のイメージ図が以下です。
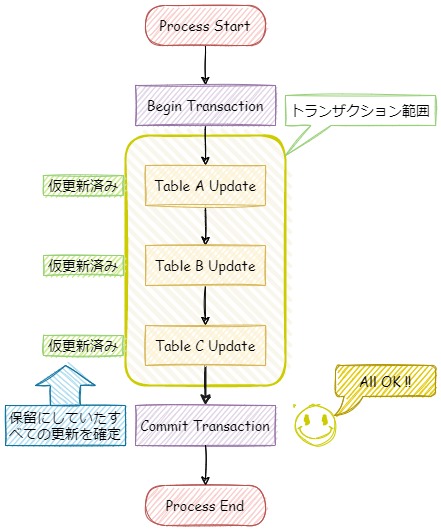
Table A から Table Cまではいったん仮更新状態になっており、「Tracsaction Commit」で初めて実際に変更が反映されます。
このトランザクション処理中は、別のプロセスからの更新は受け付けません。
さて、次は、トランザクション中の更新処理でエラーが発生した場合の処理イメージは以下です。
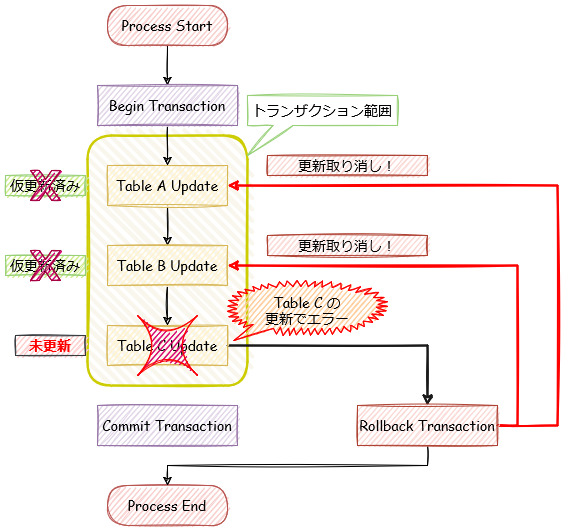
この例では、Table C の更新時にエラーが発生しています。
トランザクション処理内でエラーを検出し、「Tracsaction Rollback」に移動して、仮更新状態だったTable A と Table B に対して、更新処理の取り消し(ロールバック)を行っています。
ロールバックを発生させることで、一連の更新処理は無かったことになり、特定のテーブルだけが更新されるといった不整合を防ぐことができます。
データベースにおいて、このトランザクションやロックの仕組みは非常に重要であり、確実に理解をしておきたいところです。
トランザクション管理やロックの仕組みデータベースにとってとても重要です。
システムの信頼性に大きく影響する概念なので、しっかり理解していきましょう!
パフォーマンスチューニング
当項では、データベースの処理を速くするための「パフォーマンスチューニング」を紹介していきます。
データベースは大量のデータを管理できます。
データが少ないうちは、データを検索したり更新したりする処理に時間が掛かることも少ないのですが、データが増えていくにつれ処理に時間が掛かるようになっていきます。
データベースを使用して様々なシステムが稼働しており、データベースの処理が遅くなることで、そのシステム自体の動作やレスポンスも遅くなります。
遅くなった処理を放置すると、それは更に遅くなる一方であり、処理が遅いシステムはサーバーの負荷に繋がり、断続的に発生するユーザー操作の待ち時間が蓄積されることによりユーザーの作業効率も低下して目に見えるコスト増に繋がります。
よって、遅くなった処理は見直していく必要があります。
時間掛かるようになった処理を速くするための色々な対策の総称として「パフォーマンスチューニング」と呼びます。
このパフォーマンスチューニングを行うには、データベースに関する幅広い知識と経験が必要になり、データベースに関する経験の浅い技術者では適切に遂行することは難しいです。
しかし、データベースの性能が低下し、システムのレスポンスが悪化した際に、どの様な原因が考えられるのかを知っておき、それらに対して一般的にどのような対応が求められるのかを理解しておくことはとても重要です。
当項では、データベースの性能低下が起こる原因の例を紹介し、それに対する一般的な対応方法を説明していきます。
インデックスが効いていないSQLの実行
前編で紹介したインデックスですが、インデックスが適切に効いていないSQLであっても、データが少ないうちはそれほどレスポンスへの影響はでません。
ただ、そのシステムの稼働しだしてある程度時間が経ち、データが蓄積されていくと、徐々にその遅いSQLが目立つようになってきます。
インデックスを指定したカラムを検索条件として適切に利用することで、何百万、何千万件のレコードから目的のレコードを瞬時に探し出すことができますが、検索条件で指定したカラムにインデックスが設定されていない、又は検索条件で指定したカラムにインデックスが設定されているが適切に使われていない場合には、目的のレコードを探し出すためには対象のテーブルの全行を確認する必要があり、レコードが増えれば増えるほど検索に時間が掛かるようになります。
また、実行されているSQLでインデックスが効いていないことによる問題は、そのSQLが使われたシステムの処理が遅くなることだけではありません。
インデックスが使われずにテーブルに対して検索を掛ける場合、前述したようにテーブルに対して全行走査が走ることになります。
この全行走査は当然データベースサーバーの負荷を大きく高めます。
非効率なSQLが何度も頻繁に実行されることで、データベースサーバーの負荷も高まり、そのデータベースを使用している全システムの応答速度の低下やタイムアウトによるエラーが発生するようになります。
インデックスの効いていない非効率なSQLのやっかいなところは、データやユーザーが少ないうちは支障なく利用できているが、時間が経ち、データが増えたりユーザーが増えたりしてから問題が発生しだす遅延性の現象なところです。
以下に対応方法を紹介します。
一般的なRDBMS製品では、ある一定期間内に実行されたSQLのうち、時間の掛かっている遅いSQLの実行履歴を抽出する機能を何かしら持っているます。
その機能を利用して遅いSQLをピックアップして、それらのSQLがインデックスを適切に使用できているかを解析します。
その解析作業では、RDBMS製品ごとに解析機能を持っており、それを利用します。
解析した結果、対象の遅いSQLでインデックスが使用されていない場合に、不足しているインデックスをテーブルに追加したり、インデックスが使用されるようにSQLを見直します。
その後再度同じSQLを解析してインデックスが使われるようになれば、実際にシステムで使用されるSQL文も修正をして本番環境に適用します。
その作業を繰り返していく流れです。
このSQLチューニングは地味ですが非常に効果的です。
データベースの性能問題が発生した場合に、まず実施しておくべき対応の一つです。
ロック待ちが大量に発生している
当記事の前項で紹介した「ロック」ですが、ロック状態になった行に対して別のプロセスが更新を掛けようとした場合、その後発の更新処理は前の更新処理が終わるまで待つことになります。
RDBMSの製品によってロックにおける排他制御の仕様も異なり、ロック中の行に対してSELECTによる参照もできない場合は、後発の更新処理だけではなく、SELECTなどの参照処理でも同様に待ちが発生します。
この「ロック待ち」も待ちプロセスが増えていくとシステム全体の処理遅延に繋がります。
この「ロック待ち」自体はRDBとしての必要な仕様であり、問題の本質は、システムの処理遅延などの影響が出るほどのロック待ちが発生してしまっている大元の原因を何とかする必要があります。
例えば、前述した「インデックスが効いていないSQLが実行されている」ことにより遅いSQLがロック待ちを誘発している可能性もありますし、別の要因があるかも知れません。
よって、本来はそのロック待ちが大量に発生している大元の原因を解消するべきですが、その原因の解明には時間が掛かる可能性もあり、手っ取り早く解消する対応法も以下で紹介しておきます。
前述しましたが、ロック時の仕様はRDBMSによって異なり、例えばSQL Serverではロック行に対してSELECTも既定では許されていません。
この場合、どうしてもロック待ちが発生し易くなります。
だったら、ロック行に対しても参照を許すように処理を変えてしまえばそのロック待ちも減ることになります。
ロックされた更新前の行への参照を許すことを「ダーティリード」と呼びます。
詳しくは過去の記事でSQL Serverのトランザクション分離レベルについて解説しておりますので、こちらもご確認ください。
このダーティリードを許すように明示的に処理を変えて対応することも一つの対応方法です。
以下の過去記事では具体的なダーティリードの許す方法を紹介しておりますため、詳しくは以下のリンク先をご参照ください。
メモリー不足によるキャッシュヒット低下など
データベースにおいて、サーバーのメモリーは非常に重要な役目を果たします。
データベースに格納されたデータは、物理的なファイルとしてサーバー内のディレクトリに配置されています。
RDBMSによってこのあたりの仕様は異なりますが、データベース単位で一つのファイルに格納されていたります。
データがファイルに格納されているということは、データを読み込むにはハードディスクを読み込みに行く必要があります。
ただ、ハードディスクはパソコンやサーバーのなかの「記憶装置」と呼ばれるパーツのなかでは処理が遅い「補助記憶装置」にあたります。
データベースがリクエストの都度、ハードディスクのデータを読み込んでいては、大量のデータを瞬時に返すレスポンスは提供できません。
その為、データベースでは、頻繁に呼ばれるレコードのインデックス情報や過去にコンパイルしたSQLの情報などの様々な情報を「メモリー」内に保存しています。
また、データベースへの行の追加や変更などが発生した場合でも、一件ずつハードディスク内のファイルに書き込む訳ではなく、ある程度を「メモリー」内に溜めておき、一定間隔で後からまとめて書き込みます。
この様に、メモリーにデータベースの様々な情報を展開しておくことで、高速なメモリー内でデータベースの処理が完結し、可能な限りハードディスクの読み込みや書き込みを減らして処理の高速化を実現しています。
データベースが使用するメモリー領域を「キャッシュ領域」とも呼びます。
ただ、データベースへのメモリー割り当てが小さい場合は、キャッシュ領域に展開できるデータ量も減ることになり、本来キャッシュされるべき様々なデータはメモリーから溢れ、ハードディスクへ物理的に保管されることになります。
データベースは、キャッシュ領域を大きくできれば速くなり、キャッシュ領域が足りなければハードディスクへのアクセスが増加して一気に遅くなります。
このように、十分なサイズのメモリー割り当ては、データベースにおいて非常に重要です。
またRDBMS製品によっては、インストール直後の既定値の設定では最小のメモリサイズしか使用しない設定になっていたり、またはメモリーの空きがあれば無尽蔵にデータベースに使用する設定になっていたりとまちまちです。
どちらの場合でも、RDBMS側の設定を変更し、データベースが使用するメモリーサイズを適切に変更する必要があります。
まず、メモリーが足りているか否かの調査方法としては、RDBMS製品ごとにデータベースのメモリー使用状況をモニタリングや解析するツールやコマンドが用意されており、それを利用して調べてきます。
RDBMSが使用するメモリ領域を、一言で「キャッシュ」と呼んだりしますが、RDBMSごとにメモリ管理の仕様は異なり、そのキャッシュも用途によって細分化されており、そのサイズを調整するための様々なパラメーターが用意されています。
その為、実際の調査や対応についてはRDBMSごとに異なり、当記事では総括した説明まではできませんが、まずは物理メモリーが十分なサイズをデータベースに割り当てられているか確認し、足りていなければメモリーを追加します。
また、メモリー不足の一つの指標として、どのRDBMS製品でも解析することができる「バッファキャッシュヒット率」を見て、その値が100パーセントに近ければ近いほど良い状態であり、仮に90パーセントを下回る場合は、メモリーが足りていないのでデータベースへの割り当てメモリーの見直しや物理メモリーの追加を検討します。
I/Oボトルネックによる処理待ちキューの増加
最近では仮想環境でサーバーを稼働させることも多く、更にIaaSなどのように、物理環境をまったく意識することなくサーバーを利用するケースも多くなりましたが、物理サーバーをオンプレ環境で稼働させている場合や、仮想化をしていても、仮想ホストサーバーをオンプレ環境で稼働させている場合は、やはり物理サーバー固有の性能問題の要因についても知っておいた方がよいでしょう。
前述したメモリ不足の項でも言及しましたが、データベースのデータは物理的なハードディスクで管理されています。
大容量の物理メモリーを割り当てても、ハードディスクへのアクセスは無くなる訳ではありません。
また、メモリーの利用状況に応じて、ハードディスクへのアクセスは増えていきます。
ハードディスクへのアクセスが増加するにつれて、ハードディスク自体の読み込みや書き込み処理の遅さがやはりボトルネックになってきます。
この「ボトルネック」の具体的な状態としては、ディスクに対してデータを書いたり読んだりする場合に、内部的にはディスクに対してコマンドが投げられており、そのコマンドの処理待ち状態が発生していることを指したります。
この処理待ち状態を「キュー(Queue):処理待ち行列」と呼びます。
例えば、以下のイメージをご参照ください。
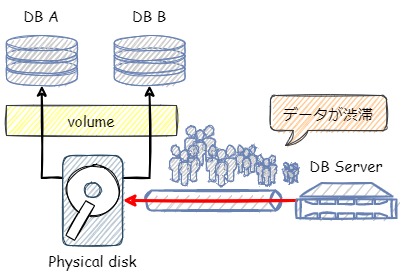
これは二つのデータベース領域を一つのディスク上で管理している構成です。
現実的には純粋に一つのディスク上にデータベースを配置して使用することはあまりなく、RAIDで冗長化されているケースが大半ですが、構成をシンプルにするために単体のディスクで表現しています。
このディスクとデータベースサーバーとは一本のケーブルで接続されており、ディスク上の二つのデータベースに対するアクセスが一つのディスクに集中していることで、データの渋滞が起きています。
これがキュー待ちの状態です。
このキューの状況は、OS側の解析ツールを使用することで確認できます。
Windows系サーバーであれば、標準機能の「パフォーマンスモニター」を使用します。
パフォーマンスモニターを起動し、カテゴリーに「Physical Disk」を指定し、カウンター名は「Queue Length」などを指定します。
この値が平均2以上であればキュー待ちが発生してパフォーマンスに影響が出ています。
これらの調査方法はOSごとやRDBMS製品ごとに異なるため、詳しい調査方法は割愛致します。
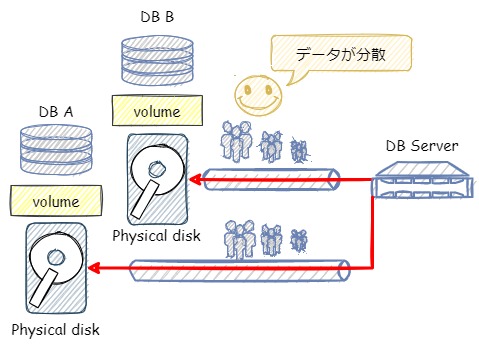
上記のように、キュー待ちが発生している場合に有効なのは、物理的にディスクを分けて、データベースを配置する対応です。
それをすることで、それぞれのディスクI/Oは分散され、キュー待ちが解消されます。
この場合の構成イメージは以下です。
その他のパフォーマンスチューニング方法
上記の内容以外にも、様々なパフォーマンスチューニング方法があるため、それらも参考がてら紹介していきます。
SQLの解析などの結果、インデックスが足りていない場合は必要なインデックスを追加します。
インデックス領域の内部的なデータは、レコードの追加、更新、削除によって断片化していきます。
断片化が進むと、インデックスを効率よく参照することができなくなり検索が遅くなります
よって、断片化が進んでいるインデックスがあれば、インデックスのデフラグや再構築を行います。
インデックス領域の内部的なデータでは、レコードの追加や変更などに伴い、ブランチノードの分割したり管理するための処理が内部的に発生しており、これらは負荷の高い処理です。
また、ノード分割時には、内部的にインデックスに対するロックも発生するため、検索や更新の処理待ちが発生します。
そのため、重要度が低い、又は不必要なインデックスが存在している場合はそれらを削除します。
SQLを都度発行する処理では、SQLの構文解析→コンパイル→実行のプロセスで処理されますが、ストアドプロシージャではストアドをデータベースに登録した時点で構文解析とコンパイルが済んでおり、高速に処理が実行できます。
また、ストアド内の一連の処理はネットワークを介さず完結するため、ほぼオンメモリーで実行します。
これらの要因により非常に高速です。
データベースでは、様々処理で一時的な一時ファイル(テンポラリファイル)やテンポラリデータベースを使用します。
SQLのGROUP BY句やORDER BY句などのよる集計や並び替え時の中間表、一時テーブルなどの一時オブジェクト、テーブル変数、ハッシュ集計操作・・・。
テンポラリ領域の設定が適切に指定されていない場合は、物理ディスクへのI/Oが増えることになり処理の遅延に繋がります。
テンポラリファイルの分割、サイズ拡張、別ディスクへの配置などの適切な調整を行うことは非常に効果的です。
これらはほんの一例であり、データベースが遅くなる原因やそれに対する対応については様々な方法があり、当記事ではお伝えしきれません。
具体的にデータベースが遅い、システムが不安定だといったことが起こりだしたら、様々な可能性を検討して、順に対応を施していくことになります。
尚、データベースのパフォーマンスチューニングは高度なデータベースに関する知識と経験が必要になり、容易に習得できるものではありません。
この記事を書いている私自身が、何度もトラブルに直面して自分の力不足を痛感していたりします。
一般的な性能問題に対する対応方法としてはどのようなやり方があるのか?
といった問いに対して、大まかに知識として知っておくだけでも、実際に問題が発生した場合に担当ベンダーとのやり取りが適切に行えたり、簡易的な対応で済むケースであれば自身で問題個所に辺りを付け、ベンダーに頼らずに自身で対応が行えるようになります。
といった状況が予想され、ピンチをピンチと正しく認識し、ベンダーに適切に報告をあげて改善の指示をする、自身でも調査するといった対応がすぐに取れるようになるのが理想です。
この記事をよく読んでいただいた良識ある読者の皆様にはきっとできると思います。
データベースのコンデションを適切に管理して、悪化した場合の対応方法を知っておくことは非常に重要です。
難しい内容ですが、しっかり理解して業務に役立てましょう!
最後に
システム管理者向けのデータベースの基礎知識や機能の紹介記事の後編を書きましたが、今回の記事で紹介した知識は比較的高度な内容も含まれています。
そのため、すべてのすぐに理解するのは難しいかも知れませんが、可能な限りデータベースにそれほど関わってこなかった非システム開発者の人でも何となく「わかった気になる」ことを目標にまとめさせていただきました。
「わかった気になる」のはとても大事で、この記事をすべての読むことで、データベースを運用したり使用するために必要な知識が点在した状態で頭に入ります。
これが「わかった気になる」状態です。
後はこの点在した知識同士を線で結ぶことで、本当にデータベースを「理解した状態」になります。
理解する前段階としての過程として「わかった気になる」状態は必要です。
今回の記事では新米システム管理者さんのお役に立てれば幸いです。
今回も長々と読んで頂きましてありがとうございました。
それでは皆さまごきげんよう!
長くて書くのが大変でした・・・。